实验一:词法分析 实验目的 实现PL/0语言的词法分析器
实验内容 PL/0语言的单词结构 关键字(共11个):空格分隔列表如下
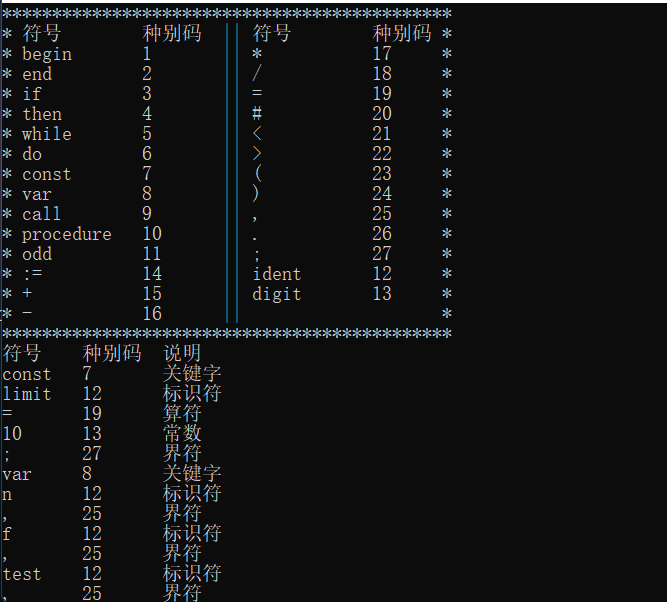
1 begin end if then while do const var call procedure odd
标识符:字母序列,最大长度10,不能与上述关键字相同
常数:整型常数
算符和界符(14个):空格分隔列表如下
1 \+ - * / = # < > := ( ) , . ;
单词种类的划分 标识符 :作为一种
常数 :作为一种
算符和界符 :每种作为一个单独种别
关键字 :每个作为一个单独种别
PL/0的语言的词法分析器将要完成以下工作 (1) 跳过分隔符(如空格,回车,制表符);
(2) 识别诸如begin,end,if,while等关键字;
(3) 识别非关键字的一般标识符。
(4) 识别常数数字序列。
(5) 识别前面列出的单字符操作符和:=双字符特殊符号。
词法分析器的实现形式 建议把词法分析器设计成一个独立子程序 ,运行一次产生一个单词符号
词法分析器的输出形式 (种别,属性值)
其中:种别在“2、单词的种别”中进行了定义;
标识符表可以简单定义为内容不重复的字符串数组。 程序的输入:可以读取标准输入,或者打开指定的源程序文件。 实验代码: 输入的测试文本文件(我的路径是:D:DesktopTest.txt)
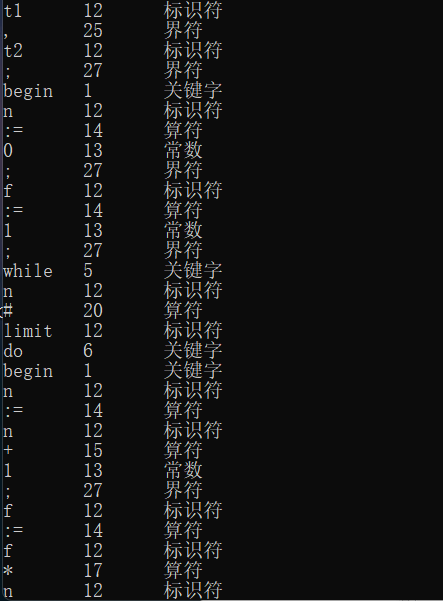
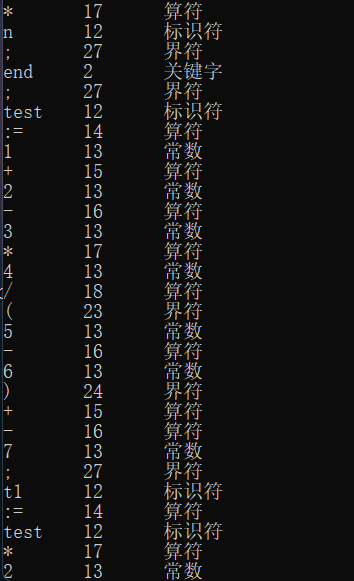
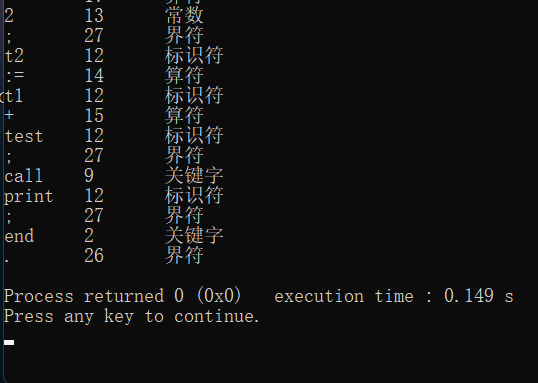
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 (* This is a multi-line comment *) const limit=10 ;var n, f, test, t1, t2; begin n := 0 ; f := 1 ; while n # limit do begin n := n + 1 ; f := f * n; end; test := 1 +2 -3 *4 /(5 -6 )+-7 ; t1:=test*2 ; t2:=t1+test; call print; end.
词法分析器实现代代码:(主要分为预处理和词法分析)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 #include <iostream> #include <iomanip> #include <stdio.h> #include <String.h> using namespace std;int main () FILE *p; int falg = 0 , len, i = 0 , j = 0 ; const char *rwtab[12 ] = {"" , "begin" , "end" , "if" , "then" , "while" , "do" , "const" , "var" , "call" , "procedure" , "odd" }; char str[1000 ], str1[1000 ], c; int syn, num; int k; char token[10 ]; if ((p = fopen ("D:\\Desktop\\Test.txt" , "r" )) == NULL ) { printf ("输入文件无法打开" ); return 0 ; } else { while ((c = fgetc (p)) != EOF) { str[i] = c; i++; } fclose (p); str[i] = '\0' ; for (i = 0 ; i < strlen (str); i++) { if (str[i] == '/' && str[i + 1 ] == '/' ) { while (str[i++] != '\n' ) {} i--; } else if (str[i] == '(' && str[i + 1 ] == '*' ) { while (!(str[i] == '*' && str[i + 1 ] == ')' )) { i++; } i += 1 ; } else if (str[i] == ' ' && str[i + 1 ] == ' ' ) { while (str[i] == ' ' ) { i++; } i--; if (str1[j - 1 ] != ' ' ) str1[j++] = ' ' ; } else if (str[i] == '\n' ) { if (str1[j - 1 ] != ' ' ) str1[j++] = ' ' ; } else if (str[i] == '\t' ) { if (str1[j - 1 ] != ' ' ) str1[j++] = ' ' ; } else str1[j++] = str[i]; } str1[j] = '\0' ; } cout << "*********************************************\n" ; cout << "* 符号 种别码 || 符号 种别码 *\n" ; cout << "* begin 1 || * 17 *\n" ; cout << "* end 2 || / 18 *\n" ; cout << "* if 3 || = 19 *\n" ; cout << "* then 4 || # 20 *\n" ; cout << "* while 5 || < 21 *\n" ; cout << "* do 6 || > 22 *\n" ; cout << "* const 7 || ( 23 *\n" ; cout << "* var 8 || ) 24 *\n" ; cout << "* call 9 || , 25 *\n" ; cout << "* procedure 10 || . 26 *\n" ; cout << "* odd 11 || ; 27 *\n" ; cout << "* := 14 || ident 12 *\n" ; cout << "* + 15 || digit 13 *\n" ; cout << "* - 16 || *\n" ; cout << "*********************************************\n" ; cout << "符号\t" << "种别码\t" << "说明" << endl; for (i = 0 ; str1[i] != '\0' ;) { j = 0 ; if ((str1[i] >= 'a' && str1[i] <= 'z' ) || (str1[i] >= 'A' && str1[i] <= 'Z' )) { while ((str1[i] >= 'a' && str1[i] <= 'z' ) || (str1[i] >= 'A' && str1[i] <= 'Z' ) || (str1[i] >= '0' && str1[i] <= '9' ) || str1[i] == '_' ) { token[j++] = str1[i++]; } token[j] = '\0' ; for ( k = 1 ; k < 12 ; k++) { if (strcmp (rwtab[k], token) == 0 ) break ; } if (k < 12 ) syn = k; else syn = 12 ; } else if (str1[i] >= '0' && str1[i] <= '9' ) { num = 0 ; while (str1[i] >= '0' && str1[i] <= '9' ) { num = num * 10 + str1[i] - '0' ; token[j++] = str1[i++]; } syn = 13 ; } else { if (str1[i] == ':' && str1[i + 1 ] == '=' ) { syn = 14 ; token[j++] = str1[i]; token[j++] = str1[++i]; i++; } else if (str1[i] == ' ' ) { i++; syn = -1 ; } else { switch (str1[i]) { case '+' : syn = 15 ; break ; case '-' : syn = 16 ; break ; case '*' : syn = 17 ; break ; case '/' : syn = 18 ; break ; case '=' : syn = 19 ; break ; case '#' : syn = 20 ; break ; case '<' : syn = 21 ; break ; case '>' : syn = 22 ; break ; case '(' : syn = 23 ; break ; case ')' : syn = 24 ; break ; case ',' : syn = 25 ; break ; case '.' : syn = 26 ; break ; case ';' : syn = 27 ; break ; } token[j++] = str1[i++]; } } token[j] = '\0' ; if (syn > -1 && syn < 12 ) cout << token << "\t" << syn << "\t" << "关键字" << endl; else if (syn == 12 ) cout << token << "\t" << syn << "\t" << "标识符" << endl; else if (syn > 13 && syn < 23 ) cout << token << "\t" << syn << "\t" << "算符" << endl; else if (syn > 22 && syn < 28 ) cout << token << "\t" << syn << "\t" << "界符" << endl; else if (syn == 13 ) cout << num << "\t" << syn << "\t" << "常数" << endl; } return 0 ; }
运行结果

 wechat
wechat