编译原理实验二
实验二:语法分析
实验目的
实现算术表达式的语法分析器
实验内容
1、PL/0文法:
在词法规则基础上,引入一组非终结符和产生式集合构成PL/0语言的上下文无关文法。
VN = { program, block, statement, condition, expression, term, factor }
其中:program 为开始符号;
VT = { ident, number, "const", "var", "procedure", "call", "begin", "end", "if", "then", "while", "do", "odd", ".", ",", "=", ";", ":=", "#", "<", ">", "+", "-", "*", "/", "(", ")" }
其中:ident 代表标识符,number 代表数值,双引号括起来的符号是源程序中出现的原始字符串(包括关键字、算符等),每个对应一个单词种别。
下面给出消除左递归和回溯的PL/0的EBNF文法,作为构造递归下降分析程序时的参考。
1 | program → block "." |
实验步骤
(1)按照EBNF文法设计语法分析程序的整体结构;
(2)针对每个语法单位编写相应的子程序,完成递归下降分析程序。
实验数据记录
写出给定文法中每个非终结符的FIRST和FOLLOW集。
FIRST集:
1 | program= {const, var,.,ident, ε ,call,begin,if,while} |
FOLLOW集:
1 | program={#} |
语法分析的结果
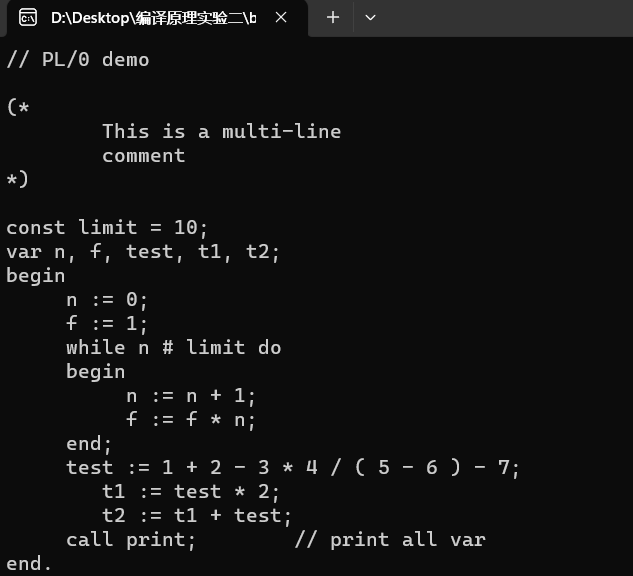
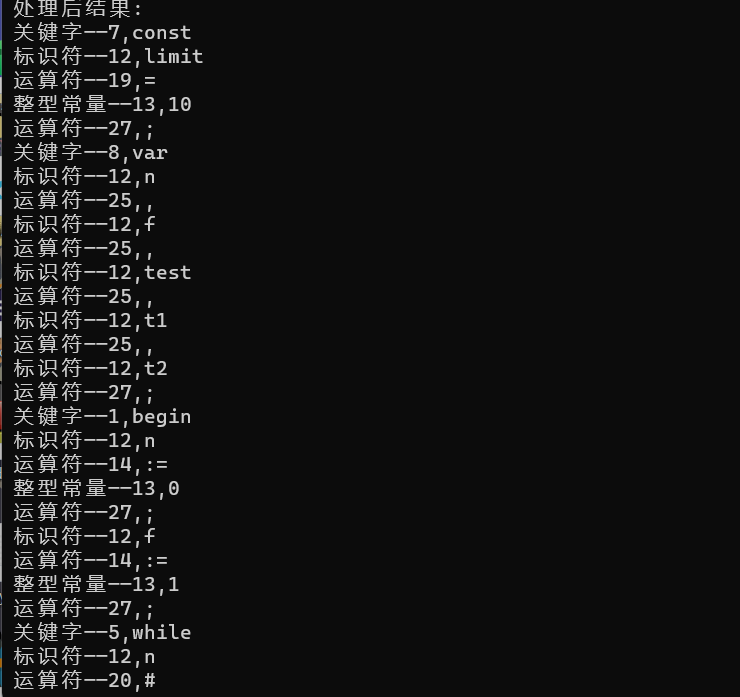
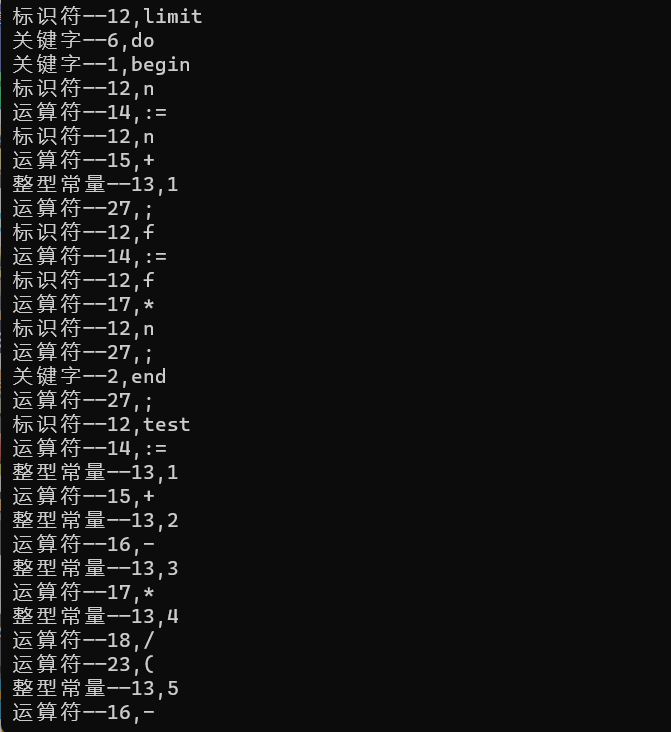
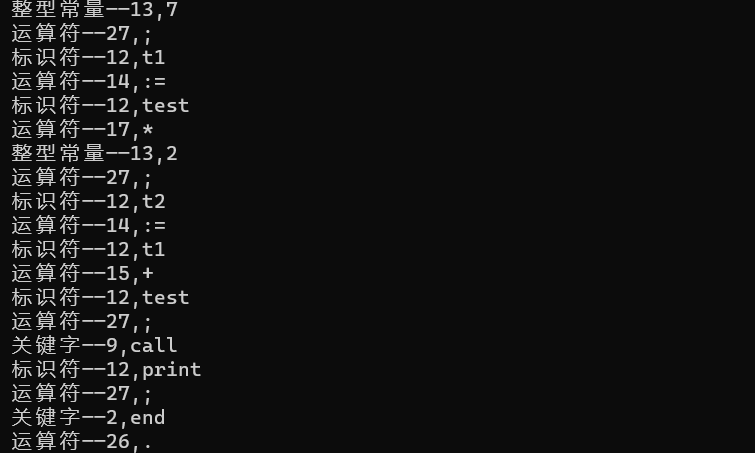
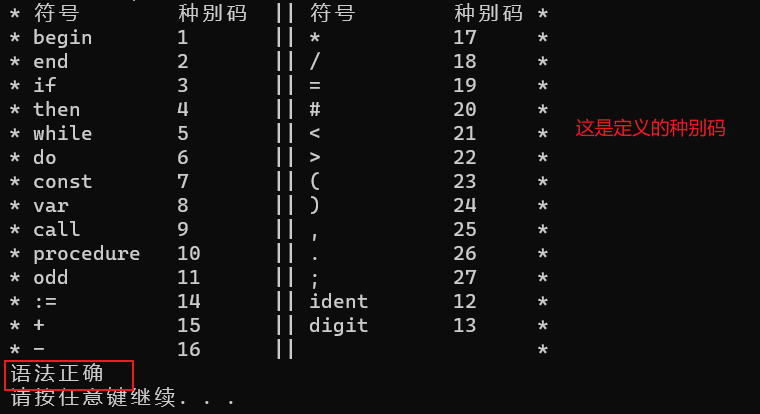
写出一段有代表性的程序并加以说明
1 | void parse_constdecl() |
源代码(仅供参考)
1 |
|
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 留白の博客!
 wechat
wechat
相关推荐

评论